
MÜNCHEN (IT BOLTWISE) – Die jüngste Forschung von Google DeepMind zu großen Sprachmodellen (LLMs) hat gezeigt, dass diese KI-Systeme beim Faktencheck von Langtexten menschliche Prüfer übertreffen können, was einen wichtigen Meilenstein in der Entwicklung wahrheitsgetreuer und verlässlicher KI darstellt.
Die Forschungsergebnisse, die in einem neuen Papier detailliert beschrieben sind, stellen einen bedeutenden Fortschritt dar. DeepMind hat LongFact eingeführt, einen Benchmark-Datensatz, der tausende von faktenorientierten Fragen über 38 Themen umfasst, generiert mithilfe von GPT-4. Um die faktische Genauigkeit der LLM-Antworten auf diese Fragen zu bewerten, schlagen die Forscher den Search-Augmented Factuality Evaluator (SAFE) vor. Diese Methode nutzt ein LLM, um eine langformige Antwort in einzelne Fakten zu zerlegen, führt eine Google-Suche durch, um unterstützende Beweise für jeden Fakt zu finden, und bestimmt die Gesamtfaktualität der Antwort durch mehrstufiges Schlussfolgern.
Wichtige Ergebnisse sind, dass LLM-Agenten supermenschliche Leistungen im Faktencheck erreichen können, wenn sie Zugang zu Google Suche haben. SAFE stimmte in 72% der Fälle mit menschlichen Annotatoren überein bei einem Set von ungefähr 16.000 einzelnen Fakten. In einer zufälligen Teilmenge von 100 Uneinigkeitsfällen lag SAFE 76% der Zeit richtig. Größere Sprachmodelle erreichen in der Regel eine bessere Langform-Faktualität. Die Studie bewertete 13 Modelle aus vier Familien (Gemini, GPT, Claude und PaLM-2) und fand heraus, dass die Modellgröße mit der faktischen Genauigkeit korreliert.
Automatisierte Faktenprüfungen mit LLMs sind deutlich kostengünstiger als menschliche Annotationen. SAFE ist mehr als 20-mal günstiger als die Verwendung von crowdsourcing-basierten menschlichen Annotatoren. Die Forscher schlagen auch vor, die F1-Punktzahl als aggregierte Metrik für die Langform-Faktualität zu erweitern. Diese Metrik, F1@K genannt, balanciert den Prozentsatz der in einer Antwort unterstützten Fakten (Präzision) mit dem Prozentsatz der im Verhältnis zu einem Hyperparameter K bereitgestellten Fakten, welcher die bevorzugte Antwortlänge eines Benutzers repräsentiert (Recall).
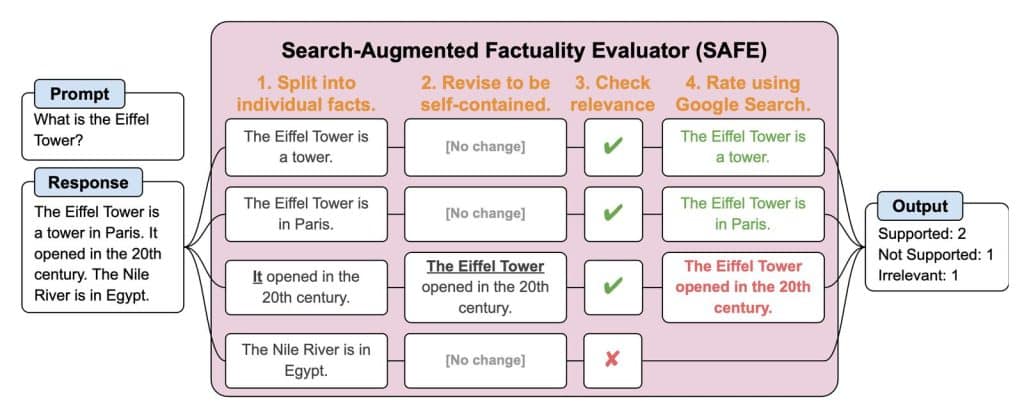
Trotz dieser vielversprechenden Schritte gibt es Einschränkungen. SAFE ist abhängig von den Fähigkeiten des zugrundeliegenden LLMs und der Vollständigkeit der Google-Suchergebnisse. Darüber hinaus geht die vorgeschlagene F1@K-Metrik davon aus, dass in der Antwort des Modells keine Faktenwiederholungen vorkommen.
Trotz dieser Einschränkungen stellt die Forschung einen vielversprechenden Schritt hin zu wahrheitsgetreueren KI-Systemen dar. Da sich LLMs weiterentwickeln, könnte ihre Fähigkeit, die faktische Genauigkeit generierter Texte zu bewerten und sicherzustellen, weitreichende Auswirkungen auf die Bekämpfung von Falschinformationen und das Vertrauen in KI-Anwendungen haben.

- Die besten Bücher rund um KI & Robotik!

- Die besten KI-News kostenlos per eMail erhalten!
- Zur Startseite von IT BOLTWISE® für aktuelle KI-News!
- Service Directory für AI Adult Services erkunden!
- IT BOLTWISE® kostenlos auf Patreon unterstützen!
- Aktuelle KI-Jobs auf StepStone finden und bewerben!
Stellenangebote
Praktikum im Team Vehicle Data and AI Solutions ab Juli 2025
Teamassistenz - Internal Audit IT, AI & Corporate Affairs (m/w/d)
Praktikant (m/w/d) Künstliche Intelligenz (KI) – Schnittstelle Data Science / Innovations- und Technologiemanagement
KI-Spezialist (m/w/d) für industrielle Anwendungen


- Die Zukunft von Mensch und MaschineIm neuen Buch des renommierten Zukunftsforschers und Technologie-Visionärs Ray Kurzweil wird eine faszinierende Vision der kommenden Jahre und Jahrzehnte entworfen – eine Welt, die von KI durchdrungen sein wird

- Künstliche Intelligenz: Expertenwissen gegen Hysterie Der renommierte Gehirnforscher, Psychiater und Bestseller-Autor Manfred Spitzer ist ein ausgewiesener Experte für neuronale Netze, auf denen KI aufbaut

- Obwohl Künstliche Intelligenz (KI) derzeit in aller Munde ist, setzen bislang nur wenige Unternehmen die Technologie wirklich erfolgreich ein

- Wie funktioniert Künstliche Intelligenz (KI) und gibt es Parallelen zum menschlichen Gehirn? Was sind die Gemeinsamkeiten von natürlicher und künstlicher Intelligenz, und was die Unterschiede? Ist das Gehirn nichts anderes als ein biologischer Computer? Was sind Neuronale Netze und wie kann der Begriff Deep Learning einfach erklärt werden?Seit der kognitiven Revolution Mitte des letzten Jahrhunderts sind KI und Hirnforschung eng miteinander verflochten



Du hast einen wertvollen Beitrag oder Kommentar zum Artikel "DeepMind zeigt: Größere KI-Modelle meistern Faktenprüfung besser als Menschen" für unsere Leser?
 #Sophos
#Sophos
Es werden alle Kommentare moderiert!
Für eine offene Diskussion behalten wir uns vor, jeden Kommentar zu löschen, der nicht direkt auf das Thema abzielt oder nur den Zweck hat, Leser oder Autoren herabzuwürdigen.
Wir möchten, dass respektvoll miteinander kommuniziert wird, so als ob die Diskussion mit real anwesenden Personen geführt wird. Dies machen wir für den Großteil unserer Leser, der sachlich und konstruktiv über ein Thema sprechen möchte.
Du willst nichts verpassen?
Du möchtest über ähnliche News und Beiträge wie "DeepMind zeigt: Größere KI-Modelle meistern Faktenprüfung besser als Menschen" informiert werden? Neben der E-Mail-Benachrichtigung habt ihr auch die Möglichkeit, den Feed dieses Beitrags zu abonnieren. Wer natürlich alles lesen möchte, der sollte den RSS-Hauptfeed oder IT BOLTWISE® bei Google News wie auch bei Bing News abonnieren.
Nutze die Google-Suchmaschine für eine weitere Themenrecherche: »DeepMind zeigt: Größere KI-Modelle meistern Faktenprüfung besser als Menschen« bei Google Deutschland suchen, bei Bing oder Google News!